

Introduction
Computer Algorithm
컴퓨터 알고리즘은 원하는 내용의 자료를 정확하고 빠르게 일련의 과정들을 처리할 수 있습니다. 거의 모든 분야에서 정보화 작업이 진행되고 있기 때문에 검색해야 하는 데이터의 양은 점점 많아지고 복잡해지고 있습니다. 주어진 문자열과 정확하게 매치되는 내용을 찾거나 처리하는 것은 시간이 매우 오래 걸리는 일이며 더 나아가 유사 매칭과 부분 매칭을 위한 검색은 더 오랜 시간이 걸립니다. 따라서 다양하고 효과적인 알고리즘에 대한 연구가 필요해지고 있습니다.
|
|
|
|
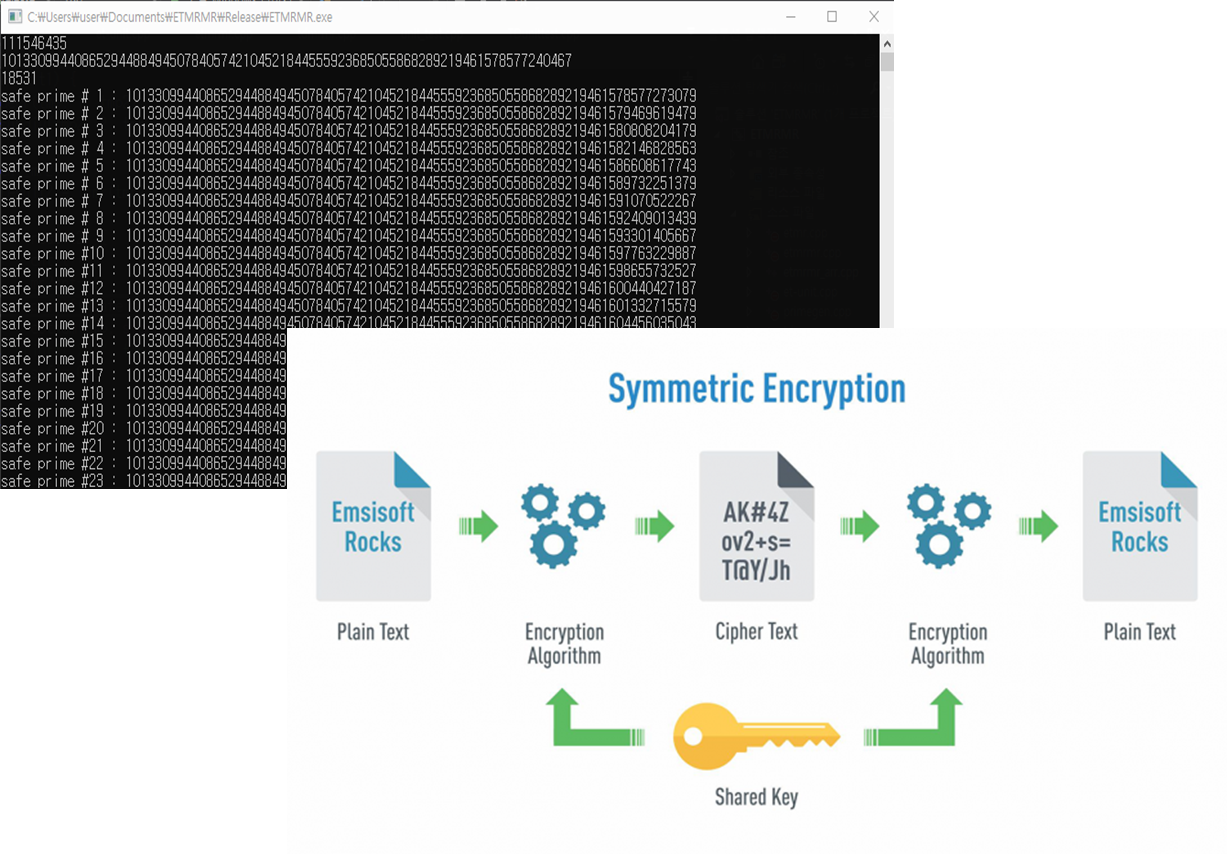
Information Security
정보보호 알고리즘은 악의적인 공격자로부터 중요한 정보를 보호하는 알고리즘입니다.
|
|
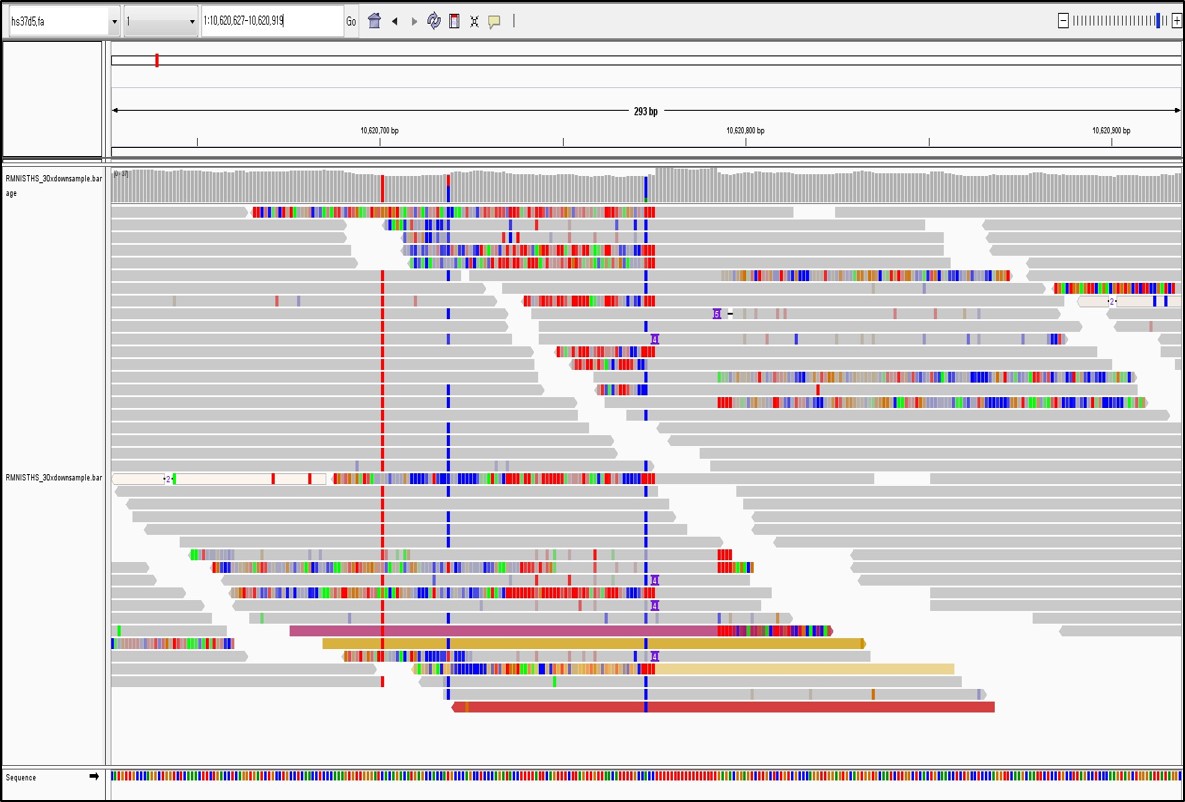
Bioinformatics
Bioinformatics는 생물정보에 대하여 컴퓨터를 이용하여 분석하는 학문으로써 현재 Genomics와 Proteomics를 연구하고 있습니다.
|
|
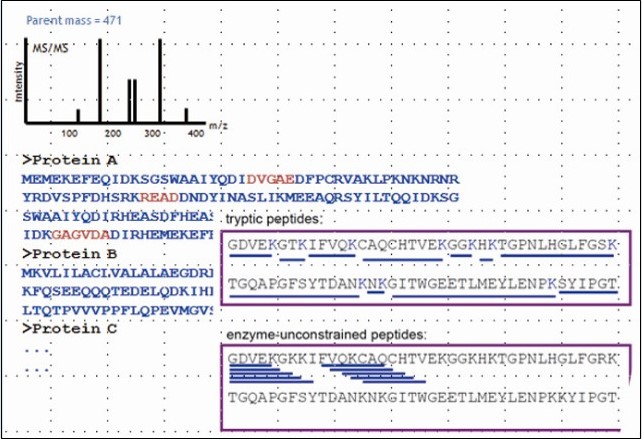
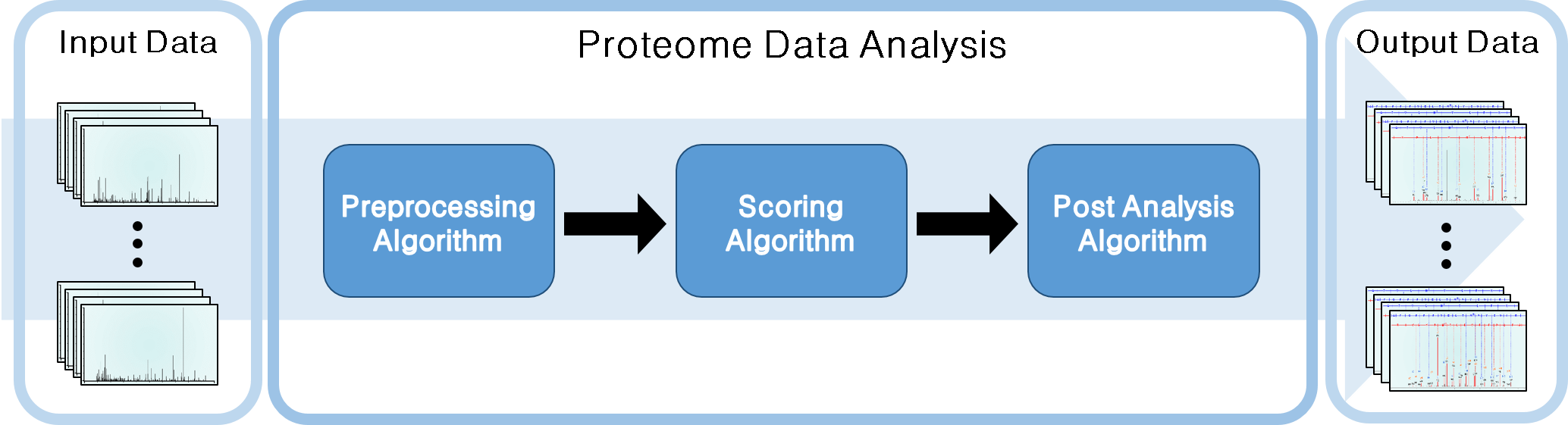
· Proteomics
|
|
|
|